自从去年10月份,我就再没写过类似编程类的文章了,python也差不多忘了
(记得22年底学会的爬虫,现在忘干净了都)不过爬虫确实是一个伟大的发明啊, 解放了多少懒人的双手
所以,今天写个爬虫练练手吧,就爬取bangumi的2024动画列表吧
研究bangumi网页特点
我个人认为,要用爬虫爬取不同网页,程序必须是类似因地制宜的。打个比方,有的网站图片习惯用img标签展示,有点则另辟蹊径,用div展示;想爬取图片只能get div标签。
正因此,不能把程序写死了,一个爬虫程序仅针对一个网页结构,各个网站结构都不同,所以在写代码前做好调查是必不可少的。
以bangumi.tv为例
我们想要爬取的是24年所有番剧的名称(用红框框框的蓝色文字)

在控制台中,我们惊奇的发现:它是在a标签中的!
<h3>里面套<a>,后边要用
开干
这就好办了,已知url为https://bangumi.tv/anime/browser/airtime/2024,获取元素位置也知道了,即可得到以下代码(辛辛苦苦加了注释,自己看吧):
# 导入库
import requests
from bs4 import BeautifulSoup
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/78.0.3904.108 Safari/537.36 '
}
# 获取网页
url = 'https://bangumi.tv/anime/browser/airtime/2024'
print(url)
response = requests.get(url, headers=headers) # 请求地址
soup = BeautifulSoup(response.text, 'lxml') # BeautifulSoup处理
# 提取链接
list = []
for img in soup.find_all('h3'): # 遍历寻找h3标签
list.append(img.find('a').text) #从刚刚获取的h3标签中找a标签
print(list)
# 注:因为网页的结构就是h3标签套a标签,类似父子标签,所以有以上操作
运行之后,惊奇的发现——

easy,忘加编码了,在请求(requests.get)后边加个编码
response.encoding = 'utf-8'
迎来了第二个问题:bangumi它是分页展示的,这就是说一个页面无法完全展示所有的番
咋办呢?
我之前说过嘛,要因地制宜,我们又惊奇的发现——
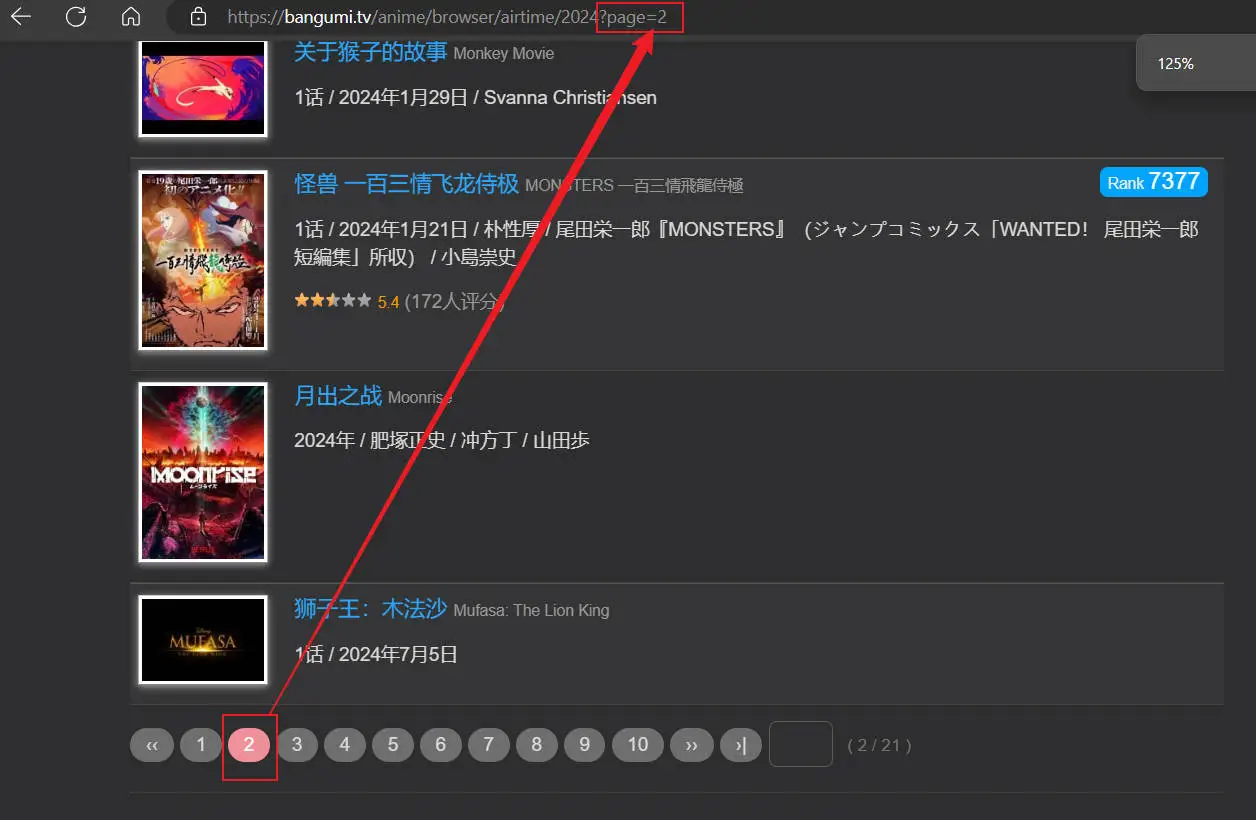
每一页都会在地址后方加上?page=页数
这个我会!遍历嘛,每次遍历让地址末尾+1,页数也就+1了嘛(遍历次数即为页数,想获取多少也就遍历多少次)
然后每次遍历都请求一次,将番名存放至列表中
(又是辛辛苦苦的加的注释…累)
# 导入库
import requests
from bs4 import BeautifulSoup
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/78.0.3904.108 Safari/537.36 '
}
# 获取网页
for n in range(3): # 遍历3次
n += 1
# 获取网页
url = 'https://bangumi.tv/anime/browser/airtime/2024?page=' + str(n) # 每次page+1
print(url)
response = requests.get(url, headers=headers) # 请求地址
response.encoding = 'utf-8' # 编码改为utf-8
soup = BeautifulSoup(response.text, 'lxml') # BeautifulSoup处理
# 提取链接
list = []
for img in soup.find_all('h3'): # 遍历寻找h3标签
list.append(img.find('a').text) #从刚刚获取的h3标签中找a标签
print(list)
# 注:因为网页的结构就是h3标签套a标签,类似父子标签,所以有以上操作

非常滴好!获取了第1、2、3页
但又出现了一个致命bug:每次遍历都会清空soup变量,导致只能把最后一页的内容给列表,前两页的都没了
咋办呢?
让它每次遍历都加到列表里呗
(不加注释了,太懒了)
import requests
from bs4 import BeautifulSoup
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/78.0.3904.108 Safari/537.36 '
}
list = [] # 储存列表
for n in range(3):
n += 1
# 获取网页
url = 'https://bangumi.tv/anime/browser/airtime/2024?page=' + str(n)
print(url)
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
for img in soup.find_all('h3'): # 遍历获取标题
list.append(img.find('a').text) # 存到列表里
print(list)
但是总不能在控制台读吧,还是把它放到txt文件里吧
import requests
from bs4 import BeautifulSoup
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/78.0.3904.108 Safari/537.36 '
}
list = [] # 储存列表
for n in range(21):
n += 1
# 获取网页
url = 'https://bangumi.tv/anime/browser/airtime/2024?page=' + str(n)
print(url)
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
for img in soup.find_all('h3'): # 遍历获取标题
list.append(img.find('a').text)
print(list)
# 写入txt
f = open('1.txt', 'w', encoding='utf-8', errors='ignore') # 别忘了encoding编码,要不又乱码了...
list = "\n".join(list) # 分词,每行一个
f.write(list)
f.close()
我看我这儿bangumi有21页,我遍历了21次

那咱的目的就达成了
改进
我又想了很多,这个程序还有很多的改进地方,比如多次递归来获取评分或发布日期,然后根据她们排序
当然,也可以通过深度优先搜索、广度优先搜索来查找番剧。不过爬虫这个东西就是因地制宜来制作程序,再怎么说也脱离不了网页的结构。
总之,这篇文章就到这里了。不过今年四月新番真不错啊!






大佬在你基础上让gpt帮改进了一下代码
现在可以自动生成文件夹了,帮我做番剧媒体库的框架
妙啊!٩(ˊᗜˋ*)و