Python实践:按固定名单顺序排序乱序分数
要求
我们班搞了个量化分,每个组长都会汇报自己组员的分数。然后作为班长的我要把全班分数合并到一张excel中。
需要注意的是,在excel中全班姓名的顺序都是固定的,但组长汇报的姓名顺序却是乱序的。这也意味着如果用传统方法的话,只能单独一个人一个人地去查找、填入数据(excel好像有函数能实现)。

但是,我们可否通过python更简易的实现呢?
实现
我们仔细想想,组长汇报的数据与统计待统计名单的姓名只是顺序不同,我们只需要让姓名对应上,然后分数也就对应好了。其实它本质上是一个批量根据固定名单顺序对数据重新排列的玩意儿。
举个例子:
| # 姓名 | # 分数 |
| 赵六 | 60 |
| 李四 | 40 |
| 孙七 | 70 |
| 张三 | 30 |
| 王五 | 50 |
| 周八 | 80 |
| # 姓名 | # 分数 |
| 张三 | |
| 李四 | |
| 王五 | |
| 赵六 | |
| 孙七 | |
| 周八 |
我想了很久都没想出来如何把姓名和数字分开。直到chatgpt提醒我有一个好东西叫正则表达式。
所以,就很好实现啦。
首先,要将组长汇报的数据(待合并的)全部放到txt文件里

然后通过正则表达式提取数据,转换成字典的形式,方面后续的操作。(感谢chatgpt帮我了大部分忙)
import re
# 从txt提取数据,转化成字典的形式
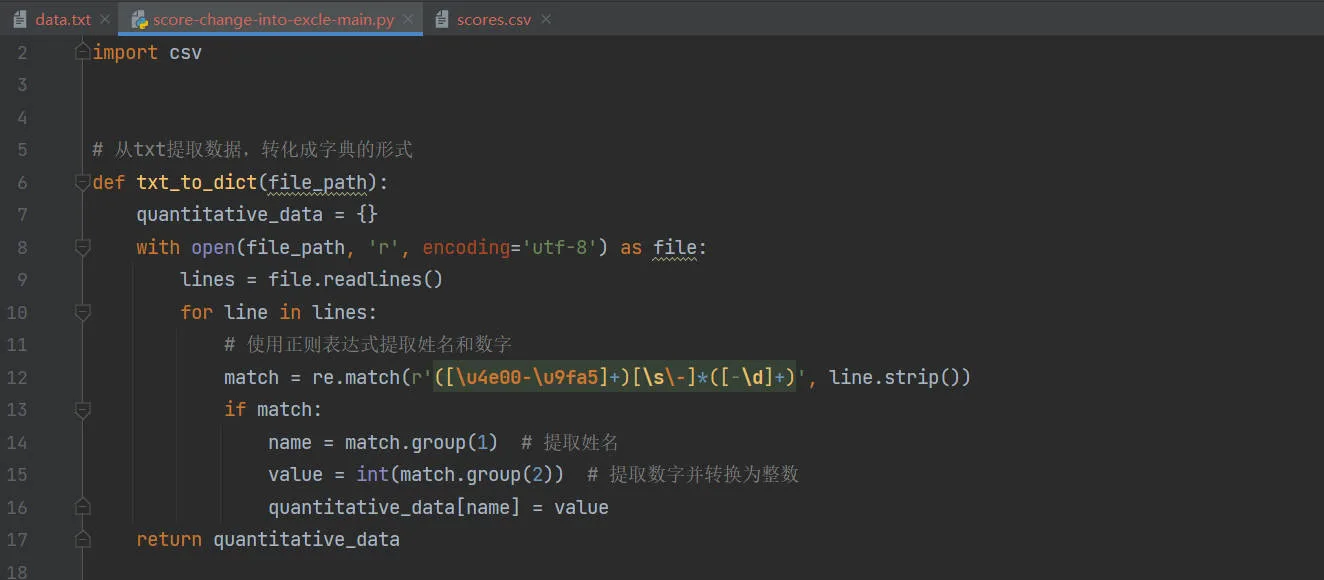
def txt_to_dict(file_path):
quantitative_data = {}
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
for line in lines:
# 使用正则表达式提取姓名和数字
match = re.match(r'([\u4e00-\u9fa5]+)[\s\-]*([-\d]+)', line.strip())
if match:
name = match.group(1) # 提取姓名
value = int(match.group(2)) # 提取数字并转换为整数
quantitative_data[name] = value
return quantitative_data
file_path = 'data.txt'
changed_score = txt_to_dict(file_path)我们就可以得到changed_score这一个字典了:
{'李四': 123, '王五': 118, '张三': 44, ......}接下来,把字典按照名单的顺序放到csv里面
(至于为何是csv格式呢?因为可以直接粘贴到excel表格中)
import csv
# 这是名单的顺序,上面的字典里边的数据按照下面的列表顺序对应起来
students = [
"张三", "李四", "王五", "赵六", "孙七", "周八"
]
# 给csv提取姓名和数据
output_data = [["Name", "Score"]]
for student in students:
# 如果没数据(或者没对应上姓名),就填上“无数据”
score = changed_score.get(student, "无数据")
output_data.append([student, score])
# 指定输出到scores.csv
output_file_path = "scores.csv"
# 写入数据
with open(output_file_path, mode="w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerows(output_data)完整代码如下:
import re
import csv
# 从txt提取数据,转化成字典的形式
def txt_to_dict(file_path):
quantitative_data = {}
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
for line in lines:
# 使用正则表达式提取姓名和数字
match = re.match(r'([\u4e00-\u9fa5]+)[\s\-]*([-\d]+)', line.strip())
if match:
name = match.group(1) # 提取姓名
value = int(match.group(2)) # 提取数字并转换为整数
quantitative_data[name] = value
return quantitative_data
file_path = 'data.txt'
changed_score = txt_to_dict(file_path)
print(changed_score)
# 指定的顺序,上面的字典里边的数据按照下面的列表排起来
students = [
"张三", "李四", "王五", "赵六", "孙七", "周八"
]
# 给csv提取姓名和数据
output_data = [["Name", "Score"]]
for student in students:
# 如果没数据(或者没对应上姓名),就填上“无数据”
score = changed_score.get(student, "无数据")
output_data.append([student, score])
# 指定输出到scores.csv
output_file_path = "scores.csv"
# 写入数据
with open(output_file_path, mode="w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerows(output_data)最后输出到scores.csv里面。
讨论区
评论审核提示:
近期垃圾评论泛滥,本站已启用严格的自动审查机制。若评论未能成功发送,可能是被误判为垃圾信息(你是故意的还是不小心的)。建议适当修改后重试,或直接给Mimosa发邮件。










































.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
























答案是=VLOOKUP(条件,匹配区域,值列号,FALSE)|´・ω・)ノ
正确ヾ(≧▽≦*)o
哦! 我的天 你真是个天才